Fuzz Testing Guide | What You Should Know

In this article in Software Testing Tutorial, we will learn What is Fuzz Testing, Phases of Fuzz Testing, How To Perform it, and the following.
What is fuzz testing with examples?
Fuzz testing is a type of security testing that discovers coding errors and security loopholes in software, operating systems, or networks.
Fuzz testing or fuzzing involves inputting massive amounts of random data called fuzz, to the software being tested to make it crash or break through its defenses.
In simple terms, large amounts of unexpected or random inputs are fed into the system, which might lead to unexpected results.
Fuzzing often reveals vulnerabilities that can be exploited by SQL injection, buffer overflow, denial of service (DOS), and cross-site scripting. Malicious hackers might havoc the system using these security vulnerabilities.
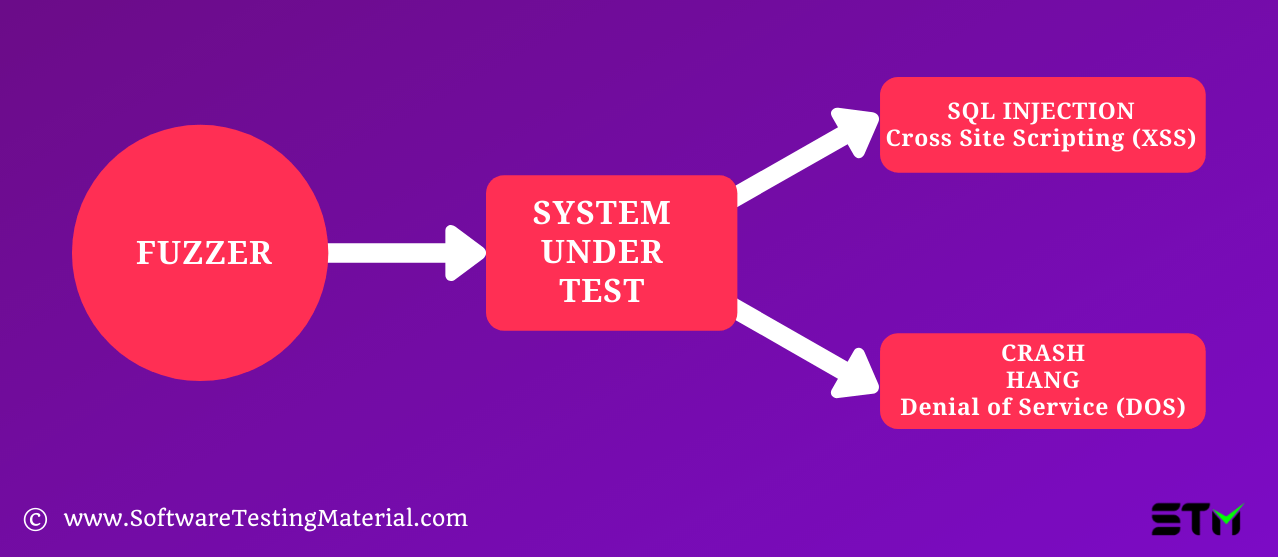
Fuzz testing is done using fuzzer, it is a program that automatically injects semi-random data into a program and detects bugs.
Fuzz testing is usually done automated.
Phases of Fuzz Testing
The objective of this Fuzz testing is to identify the critical security level faults in the software application.
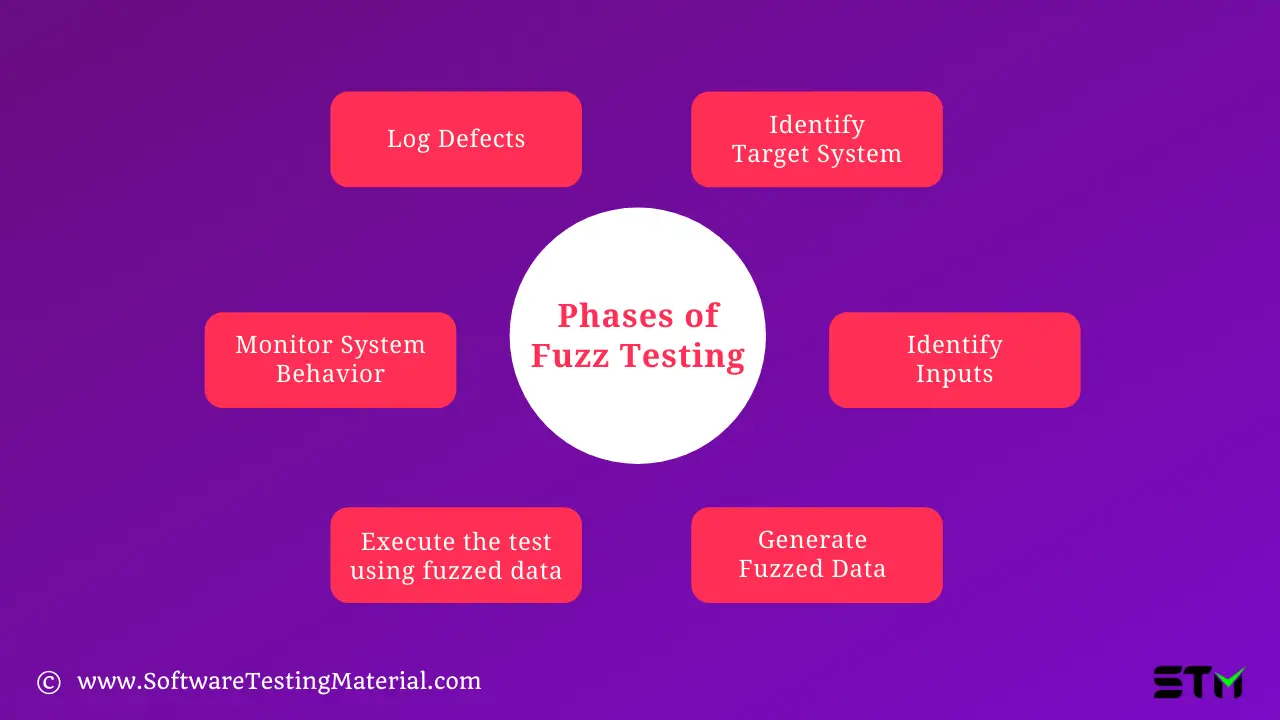
Identify Target System
Here the target system would be the software under development or an external dependency of it. The targeted component can typically be reached through several interfaces and protocols.
Identify Inputs
After deciding on the target system i.e the interface through which the input data is inserted, we have created input data for such fields. Random inputs are created for testing the application.
Generate Fuzzed Data
Random inputs created in the previous step are fuzzed i.e unexpected invalid values are inserted.
Execute the test using fuzzed data
These fuzzed data is used for the testing purpose. The application is executed with fuzz data as the input values.
Monitor System Behavior
The behavior of the system is observed for potential security vulnerabilities, memory leaks, and crashes after the test case execution.
Log Defects
Defects are logged in this phase. These issues are addressed for a better quality of the product.
Benefits of Fuzz Testing
- Fuzz testing saves the application from malicious intentions of hackers, by identifying security vulnerabilities.
- Fuzz testing usually complements other testing techniques (like Black Box Testing), more errors can be identified with such conjunctions.
- By fuzzing the system, the unexpected output will be triggered, such outputs are never designed by the developer.
- Fuzz testing often reveals serious defects which are usually overlooked while developing the software, hence it offers a high benefit-to-cost ratio.
Why do we do Fuzz Testing?
- To uncover serious security faults or defects.
- To save the application from security breaches.
- To check the vulnerability of the software.
- To provide the application maximum coverage.
- To find the utmost defect at a low cost.
- To ensure that the system is robust.
- To detect memory-related errors in the application.
- To detect race conditions and deadlocks in the system threads.
- To verify undefined behavior in the output.
- To control memory leaks in the application.
- To understand control-flow integrity-related issues.
How to perform Fuzz Testing
Fuzz testing takes place in the interface which accepts data. Here the interface can be an external link like a network connection or a file or something internal like a function calling conventions in a utility library.
For the chosen interface, fuzzed data is inserted to see how the interface handles those invalid inputs.
Threat modeling and sketching a data flow diagram can help us in discovering the potential interface.
Behind each interface, there can be many layers of software. It is crucial to identify which layer of the software we are targeting to create an input that can pass through all checks on previous layers.
Let’s take an example here, an HTTP server accepts a signed BLOB (Binary Large Object) of data. In that blob, we have a JSON string that contains values that are used by our application.
We have four potential layers to fuzz here in this example:
1. HTTP messages for the server
2. Signing check for our data blob
3. JSON string parsing
4. Our code handling the actual values
In this example, we are not targeting our HTTP, signing, and JSON libraries.
We are fuzzing our code to generate the values, pack the values into JSON string, sign the blob, create an HTTP message and send it to the target implementation.
If we don’t have a proper automation suite, we have to build those cases and inject fuzzes into them, this might take a considerable amount of time. Here we should not fuzz the whole stack, it might lead to constant overhead and it may break when some of the layers are changed.
It focuses on the throughput of test cases and we should also consider the functionalities in the target program that could be disabled or bypassed to reduce the overhead and increase coverage achieved by the fuzzer.
When looking at our example, we have to create a program that directly passes values to our handling code, bypassing the network message, a couple of hash calculations, the cryptographic check, JSON stringify, and JSON parsing.
We have to make sure that these changes don’t hide or create new bugs because there can be altered behavior in the target when implementing fuzzing optimization.
An effective way to start fuzzing is to spew random data to any interface that we can find rather than injecting thousands of test cases per second into an optimized fuzzing environment.
Examples of Fuzzers
Mutation-Based Fuzzers:
This type of fuzzer is the easiest one to create, as it alters existing data samples to create new test data. It comes under dumb fuzzing, but it can be used with more intelligent fuzzers. We can do this by making some level of parsing of the samples to ensure it only changes specific parts or doesn’t break the overall structure of the input.
Generation-Based Fuzzers:
This type of fuzzer requires more intelligence to create test data from scratch i.e new test data is created based on the input model. It usually splits a protocol or file format into chunks, which is then build into a valid order and those chunks are randomly fuzzed independently
Protocol-Based Fuzzers:
It is an efficient technique, based on the knowledge of the protocol format new test data is designed and prepared. It generally involves writing the specification in an array form into the tool and thereafter based on the specification, adding distortion or flaws in the input data, pattern, series, etc.
Types of bugs detected by Fuzz Testing
Fuzz testing is traditionally to check for memory-corruption bugs. Nowadays in modern applications, we focus more than just on security bugs. Here is some type of bugs that can be detected by combining fuzzing with other types of testing:
Memory-corruption and safety bugs:
Critical security bugs like heap-based buffer overflow, stack-based buffer overflow, use after free along with uninitialized variables, and integer overflow can be found.
Scheduling bugs:
Bugs like Race Condition, Hang, Livelock can be detected due to fuzz testing.
Assertions:
Some assertion bugs can be found in production(web browser), these are usually found in debug build.
Performance bugs:
Prolonged use of OS without reboot can affect the disk operating system of OS, which results in Memory leaks.
Web and mobile GUI security bugs:
It can also reveal bugs like Cross-Site Scripting (XSS), SQL Injection, XPATH Injection, PHP Code Injection, and Shell Command Injection.
Advantages of Fuzz Testing
- Improves the security of the application
- It helps in identifying critical security breaches including memory leak, an unhandled exception, etc.
- Fuzz testing helps us to make sure that our application is robust and secure.
- Fuzz testing reveals severe vulnerabilities in the application that could be easily exploited by hackers
- It helps in identifying issues that are completely overlooked by the testing team.
- It provides us with a clear picture of the overall robustness of the software application.
- Fuzz testing can catch even logical bugs if implemented at the application level.
Disadvantages of Fuzz Testing
- It doesn’t identify security threats that do not cause program crashes, such as some viruses, worms, Trojan, etc.
- It is very difficult to set boundary value conditions with random inputs.
- Fuzz testing requires a significant amount of time to be executed properly, it won’t be efficient if you have less time
- It usually reveals very simple faults that could easily be found by penetration testing.
- It can be difficult to interpret data from fuzz testing.
- It needs time, effort, and labor to implement it effectively.
- It is difficult to analyze the crashing test case and it doesn’t give us much knowledge of how the software operates internally
Fuzz Testing Tools
Open Source
Mutational Fuzzers:
- American fuzzy lop
- Radamsa – a flock of fuzzers
- APIFuzzer – fuzz test without coding
- Jazzer – fuzzing for the JVM
Fuzzing Frameworks
Domain-Specific Fuzzers
Commercial products
- Codenomicon’s product suite
- Peach Fuzzing Platform
- Spirent Avalanche NEXT
- Beyond Security’s beSTORM product
- ForAllSecure Mayhem product
- CI Fuz
Conclusion
In nutshell, fuzz testing can be done by inserting malformed, unexpected, sometimes random, inputs into a program in the hopes of triggering new or unforeseen code paths, and bugs. Fuzzing is an old technique but a commonly used one, as it is a very efficient technique for finding bugs, Fuzz testing has to be integrated into our development process to get the maximum results.
Related posts:
- Security Testing Tutorial | Software Testing Material
- 100+ Types of Software Testing – The Ultimate List
- Drag And Drop Using Actions Class In Selenium WebDriver